DeepMine Project
DeepMine is a large-scale database in Persian and English, with its current version containing more than 1400 speakers and 370 thousand recordings overall. DeepMine has several appealing characteristics which make it unique of its kind. First of all, it is the first large-scale speaker recognition database in Persian, enabling the development of voice biometrics applications in the native language of about 110 million people. Second, it is the largest text-dependent and text-prompted speaker recognition database in English, facilitating research on deep learning and other data demanding approaches. Third, its unique combination of Persian and English makes it suitable for exploring domain adaptation and transfer learning approaches, which constitute some of the emerging tasks in speech and speaker recognition. Finally, the extensive annotation with respect to age, gender, province, and educational level, combined with the inherent variability of the Persian language in terms of different accents are ideal for exploring the use of attribute information in utterance and speaker modeling.

DeepMine Database
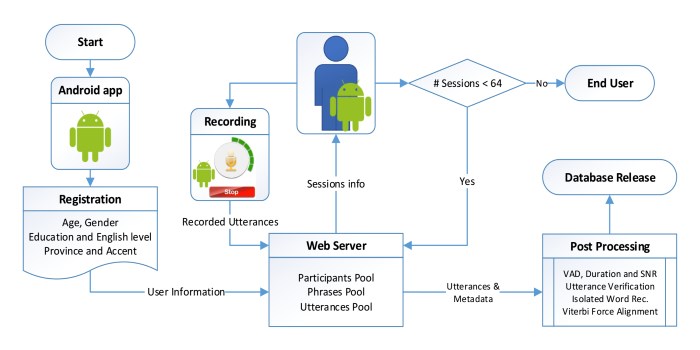
Inspired by the RedDots project, we decided to create a multi-purpose public speech database including a large number of speakers. The main goal of the project is to collect speech from at least a few thousand speakers, enabling research and development of deep learning methods. Speech data is collected from the participants online with user interfaces such as web or mobile applications (i.e. crowdsourcing). The DeepMine project started at the beginning of 2017, and after the designing of the database and the development of an Android application and server programs, data collection was begun at mid of 2017. The duration of the project was chosen to be one year but it is possible that it will be extended for several months. The first release of the dataset is planned for the fourth quarter of 2018.
How and When you can access the database
As mentioned before, the project is running now and the first phase of it should be finished by the end of summer. Post-processing of the database needs several months and so we plan the first phase release of the database at the end of 2018. We will try to process the database very quickly and it is possible that the database will be ready in autumn. Anyway, we promise to process and release the database at most by the end of the year. If you are interested in the unprocessed data, we can provide access to the last snapshot of the database. You can communicate with us to discuss about this possibility.
For access to the database, you should sign a licence agreement which will be prepared later. Also, you should pay the licence fee of the database. There will be at least two licence types for academic and commercial users. For more information, please communicate with us by email to hsn zeinali
zeinali gmailcom
gmailcom